
Challenge Description
Query by Vocal Imitation enables users to search a database of sounds by recording a vocal impression of the desired sound. The system then retrieves sounds similar to the users recording. This offers sound designers an intuitively expressive way of navigating large sound effects databases. We invite participants to submit systems that accept a vocal imitation query and retrieve a perceptually similar recording from a large database of sound effects. Final rankings of submissions will be determined by a subjective evaluation using a larger, unlabeled dataset. This challenge is part of the AES AIMLA Challenge 2025. The key dates are as follows:
- Challenge start: April 1, 2025
- Challenge end: June 15, 2025
- Challenge results announcement: July 15, 2025
Submissions
Participants are required to submit a technical report detailing the datasets and methods used in development, as well as a Jupyter notebook containing the system itself.
- Technical Specifications: A5000, GPU memory 24GB.
Detailed instructions are provided in the submission templates containing the baseline implementations. Learn more about the submission process here or click on the icon below. The submissions will be opened two weeks before the challenge deadline, during which time participants will be able to submit their system to check that their submitted code is running correctly. Each team may submit up to three different systems.
Baselines
We provide a repository containing the baseline system for the AES AIMLA Challenge 2025. The architecture and the training procedure is based on "Improving Query-by-Vocal Imitation with Contrastive Learning and Audio Pretraining" (DCASE2025 Workshop). Check the repository for the details of the baseline system. Here: Baseline of QVIM.
You can find out how the evaluation results are
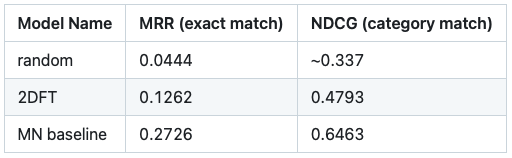
Also, here's a list of pre-trained audio embedding models that participants might find interesting.
- Mobile-Net: : Extracts features via a dual-encoder architecture consisting of two MobileNets pre-trained on AudioSet and fine-tuned on vocal imitations via contrastive learning. Learn more about MobileNet.
- 2DFT: A purely signal-processing-based representation, calculated as the 2D Fourier transform of the constant-Q transform of the audio signal. Learn more about 2DFT.
- AST: https://github.com/YuanGongND/ast
- BEATs: https://github.com/microsoft/unilm/tree/master/beats
- EfficientAT: https://github.com/fschmid56/EfficientAT
- PaSST: https://github.com/kkoutini/PaSST
- BYOL-A: https://github.com/nttcslab/byol-a
- PANNs: https://zenodo.org/records/3987831
- CLAP: https://github.com/LAION-AI/CLAP
Datasets
Participants are welcome and encouraged to utilize any publicly available dataset. We DO NOT encourage the use of private datasets.
Public Datasets:
- VocalSketch: https://zenodo.org/records/1251982
- Vocal Imitation Set: https://zenodo.org/records/1340763
- VimSketch (VocalSketch+Vocal Imitation Set): https://zenodo.org/records/2596911
- AudioSet: https://research.google.com/audioset/
DEV Dataset Overview Number of Imitations: The dataset contains a total of 985 unique imitation audio files across the three query columns (Query 1, Query 2, Query 3). Number of References: The dataset includes 121 unique reference sound files listed under the Items column. Matching Relationship Each row in the CSV file maps one reference sound (Items) to up to three corresponding vocal imitation files (Query 1, Query 2, Query 3). Multiple rows may have the same reference sound but different imitation files, indicating that the same sound may have been imitated multiple times by different participants. The DEV dataset is useful for evaluating the consistency and accuracy of vocal imitation by comparing the generated imitations with the original reference sounds.
Our dataset is available for download with the csv and the description of how the csv works in the following link:
- DEV: Download DEV Dataset.
Papers
We highlight some papers that participants may find relevant for this task
- Greif, J., Schmid, F., Primus, P. and Widmer, G., 2024: Improving Query-by-Vocal Imitation with Contrastive Learning and Audio Pretraining. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2024 Workshop (DCASE2024), 51-55. https://dcase.community/documents/workshop2024/proceedings/DCASE2024Workshop_Greif_36.pdf
- Zhang, Y., Hu, J., Zhang, Y., Pardo, B. and Duan, Z., 2020: Vroom! a search engine for sounds by vocal imitation queries. In Proceedings of the 2020 Conference on Human Information Interaction and Retrieval (pp. 23-32). https://dl.acm.org/doi/pdf/10.1145/3343413.3377963
- Pishdadian, F., Seetharaman, P., Kim, B., & Pardo, B., 2019: Classifying Non-speech Vocals: Deep vs Signal Processing Representations. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), 194–198. https://dcase.community/documents/workshop2019/proceedings/DCASE2019Workshop_Pishdadian_51.pdf
- Kim, B. and Pardo, B., 2019: Improving content-based audio retrieval by vocal imitation feedback. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4100-4104). https://ieeexplore.ieee.org/abstract/document/8683461
- Zhang, Y., Pardo, B. and Duan, Z., 2018: Siamese style convolutional neural networks for sound search by vocal imitation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(2), pp.429-441. https://ieeexplore.ieee.org/abstract/document/8453811
Prizes

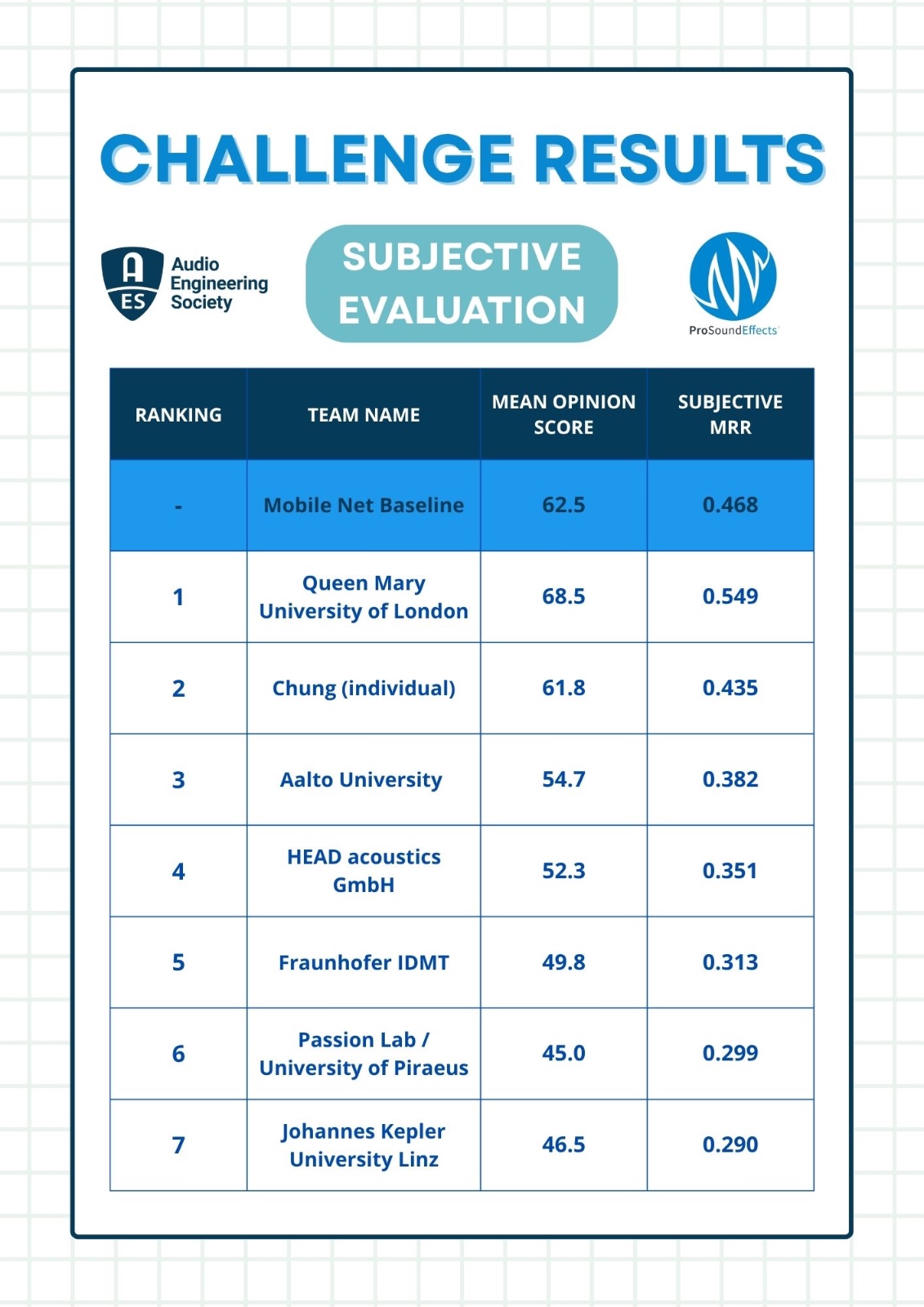
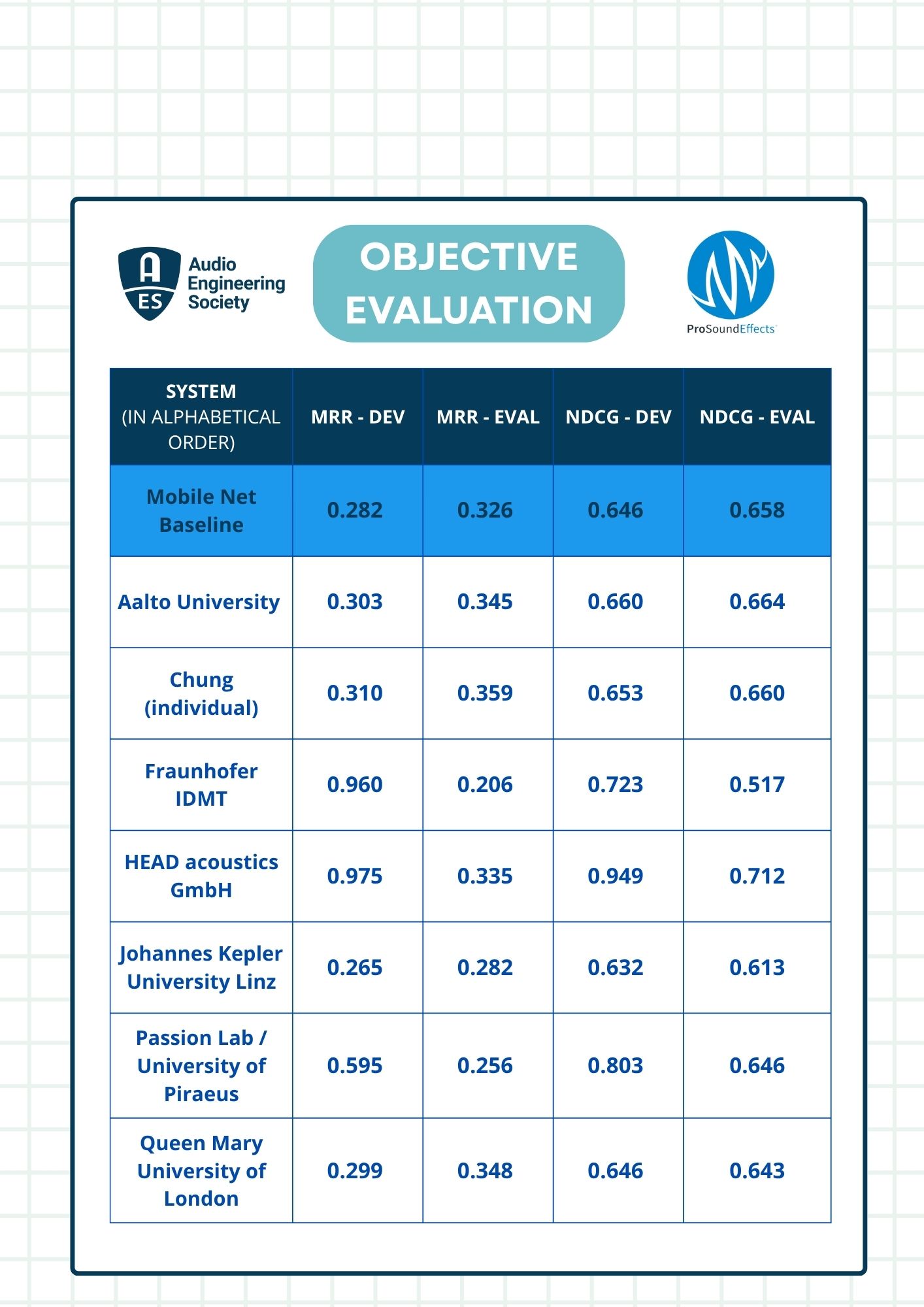
QVIM Challenge 2025 – Official Results
We are proud to announce the teams that successfully completed the QVIM Challenge, held as part of the AES AIMLA Conference.
Thank you to all participants for your innovation and dedication. Your contributions have advanced the field of query-by-vocal-imitation (QVIM) in meaningful ways.
We are sharing both objective and subjective evaluation results. A detailed report will be published in the AES AIMLA Conference Paper Track.
For full transparency, no teams affiliated with the organizers’ university were contacted or received any assistance during the challenge. QVIM remains committed to fairness and academic integrity.
Congratulations to all the teams on this achievement!

Team Members

Promotion Partner

Registration
Wanna participate? Let us know. Register your team by clicking the button below. It is important to note that the registration is free of charge. This form will help the organizers to keep track of the participants and send updates about the challenge.
Contact
Got any questions?